Understanding AI Development at a Glance
Before diving into specifics, let’s establish what we mean by “artificial intelligence development.”
What does AI development mean? It’s the process of creating software systems that can learn from data, identify patterns, and make decisions with minimal explicit programming. Instead of writing code that says “if X happens, then do Y,” developers build systems that learn to recognize when X happens by analyzing thousands of examples.
This fundamental shift, from explicit instructions to learned patterns, is what makes AI development different from traditional software engineering. It requires different skills, different tools, different testing approaches, and a different mindset about how software can behave.
AI systems typically fall into several categories:
- Machine learning models that predict outcomes based on historical data (will this customer churn? Is this email spam?)
- Large language models that understand and generate human language
- Computer vision systems that interpret images and video
- Recommendation engines that suggest products, content, or connections
- Automated decision systems that handle classification, routing, or prioritization tasks
Each category has its own development challenges, but they share common underlying principles and processes.
How Does AI Development Work? The Core Difference
Traditional software development follows a straightforward path: requirement → design → code → test → deploy. Each step is relatively predictable, and once you write a rule, it behaves consistently.
AI development introduces significant variables at every stage. Here’s why:
The Role of Data
Traditional code is deterministic. Machine learning systems are probabilistic. They improve with more data but can degrade if that data contains biases or inconsistencies. Your development team must become obsessed with data quality because it directly determines system quality.
A traditional feature might fail because of a bug in the code. An AI system might “fail” because the training data didn’t represent a particular customer segment, or because the real-world environment shifted since training occurred. This is both powerful and precarious.
Model Training vs. Code Compilation
When developers write traditional software, they compile code and run tests. With AI, developers train models on data. This training process is iterative and involves constant experimentation:
- Train a model on available data
- Evaluate its performance against test data
- Adjust model architecture or training parameters
- Repeat dozens or hundreds of times
- Gradually improve accuracy and reliability
This is fundamentally different from writing code once and running it forever. Models require ongoing monitoring, retraining, and refinement as real-world conditions change.
Uncertainty in Performance
When you deploy traditional software, you know exactly what it will do. When you deploy an AI system, you know its probable accuracy based on testing, but you accept some degree of uncertainty. A 95% accurate system will make mistakes on 5% of cases. Your business process must accommodate this reality rather than expecting perfect accuracy.
The AI Development Pipeline: Key Stages
Now let’s walk through the actual stages of building AI solutions. Understanding this AI development pipeline helps you grasp realistic timelines, resource requirements, and potential risks.
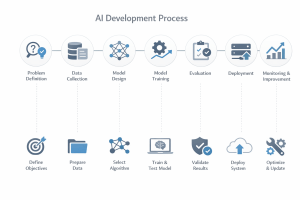
Stage 1: Problem Definition and Scoping
The first mistake many organizations make is jumping straight to models. Instead, successful AI development begins with clarity about the business problem.
During this stage, you answer questions like:
- What specific business problem are we solving?
- What would success look like numerically?
- Do we have data to support this project?
- Is AI actually the right approach, or would traditional software work better?
- What are the risks if the system performs poorly?
This stage might seem like overhead, but it’s critical. A poorly scoped AI project can consume millions in resources and still fail to deliver business value.
A practical example: A retail company might initially ask, “Build an AI system to improve sales.” That’s too vague. After proper scoping, they might refine it to: “Build a recommendation engine for e-commerce product pages that increases average order value by 15% within 6 months, using historical purchase and browsing data.”
The difference is night and day. The second version has measurable success criteria, acknowledges constraints (6-month timeline), and identifies the specific resource type (historical data).
Stage 2: Data Collection and Preparation
This is where most AI projects spend 60-80% of their time, and it’s unglamorous work that doesn’t involve fancy algorithms.
Your team must:
- Identify required data: What information does the system need to learn? For a customer churn prediction model, you might need purchase history, customer service interactions, email engagement, and account metrics.
- Gather data from disparate sources: Most companies store data across multiple systems: CRM platforms, data warehouses, transaction databases, analytics tools. Connecting these sources requires engineering work.
- Clean and standardize data: Real data is messy. Fields have inconsistent formats, records have missing values, and inconsistencies exist across data sources. This cleanup process is both critical and time-consuming.
- Create labeled examples: For supervised learning models, you need examples where the outcome is already known. Building a fraud detection system requires historical examples of fraudulent and legitimate transactions. A hiring recommendations system needs examples of successful and unsuccessful hires.
- Handle bias and imbalance: If your training data overrepresents certain groups or outcomes, your trained model will inherit those biases. Your team must actively identify and mitigate these issues.
Professional AI development teams often use tools like Python data libraries (Pandas, NumPy), cloud data platforms (Google BigQuery, Amazon Redshift), and specialized data validation frameworks to manage this stage.
Stage 3: Model Selection and Architecture Design
Once data is prepared, your team selects an appropriate model architecture. This is where machine learning frameworks like TensorFlow, PyTorch, and scikit-learn come into play.
Different problems require different approaches:
- Structured data predictions (will this customer buy?) typically use tree-based models (Random Forest, XGBoost) or neural networks
- Language understanding uses transformer-based architectures like BERT or GPT variants
- Image analysis uses convolutional neural networks
- Time series forecasting uses recurrent networks or attention-based models
Your team must select an architecture that matches the problem complexity and your data volume. Starting with simpler models is usually wise, a well-tuned simple model often outperforms a complex one that’s poorly tuned.
This stage also includes deciding whether to build from scratch, fine-tune an existing model, or use a pre-built platform. Many modern AI projects use transfer learning—taking a pre-trained model built by companies like Google, Meta, or OpenAI and adapting it to your specific problem. This significantly reduces training time and data requirements.
Stage 4: Model Training and Experimentation
This is the iterative phase where your team systematically improves the model.
The process resembles scientific experimentation:
- Define a baseline – How does a simple model or rule-based approach perform?
- Train initial models – Apply your selected architecture to prepared data
- Evaluate performance – Measure accuracy, precision, recall, or other relevant metrics
- Analyze failures – Where does the model make mistakes? Are there patterns?
- Adjust and iterate – Modify the model architecture, training parameters, or data based on insights
- Repeat – Train again with adjustments and measure improvement
This cycle might repeat 50+ times before reaching acceptable performance. Modern ML frameworks make this iteration faster, but it still requires patience and scientific rigor.
Throughout this stage, your team maintains strict separation between training data (used to build the model), validation data (used to tune parameters), and test data (used to evaluate final performance with data the model has never seen). This prevents overfitting, where a model memorizes training data but fails on new data.
Stage 5: Evaluation and Validation
Before deploying, your team must validate that the model actually solves the business problem with acceptable accuracy.
This involves:
- Performance metrics: Does the model meet your accuracy targets?
- Business metrics: Does improved model accuracy translate to the business outcome you wanted? (A recommendation engine might be 95% accurate but still fail to increase order value if users ignore recommendations)
- Edge case testing: How does the model handle unusual or extreme inputs?
- Bias auditing: Does the model perform equally well across different customer segments, demographics, or data distributions?
- Stress testing: Can the system handle production-scale data volumes and request rates?
Responsible AI development includes fairness audits, ensuring the system doesn’t discriminate against protected groups or make systematically biased decisions. A credit approval system that denies loans to qualified applicants from certain neighborhoods, even unintentionally, creates legal and ethical risks.
Stage 6: Deployment and Integration
Getting a model into production is not trivial. Your team must:
- Package the model – Convert the trained model into a format that production systems can use
- Set up inference infrastructure – Create systems that apply the model to new data in real time or batch processes
- Establish monitoring – Track how the model performs after deployment
- Plan rollback procedures – Prepare to revert if serious issues emerge
- Document the system – Create operational runbooks for your team
For example, a recommendation engine doesn’t exist in isolation, it must integrate with your e-commerce platform, load product data, consider inventory, fetch user history, and return results fast enough that customers don’t experience delays. This integration work is substantial and often underestimated.
Stage 7: Monitoring and Continuous Improvement
Deployment is not the end, it’s the beginning of operational management. AI systems require ongoing attention because real-world conditions change.
Your team monitors:
- Model performance degradation – Does accuracy decline over time? (This often happens as customer behavior or market conditions shift)
- Data drift – Are current data patterns different from training data patterns?
- System health – Are inference servers responding quickly? Are error rates acceptable?
- Business metrics – Is the deployed model still driving the business outcome it was designed for?
When performance degrades, your team retrains the model with newer data, adjusts parameters, or potentially redesigns the system entirely. This is not a one-time effort—it’s an ongoing operational responsibility.
Typical Technologies in AI Development
Understanding the tools involved helps you evaluate vendors and have more informed conversations with your technical teams.
Programming Languages
Python dominates AI development because of its ecosystem of specialized libraries. Companies like Meta, Google, and OpenAI have contributed frameworks that make AI development more accessible.
- Python – The de facto standard, with rich libraries for ML workflows
- SQL – Essential for data extraction and preparation
- Java/Scala – Used for big data processing and some production systems
- C++ – Used for high-performance inference
Machine Learning Frameworks
These libraries provide pre-built components for building AI systems:
- TensorFlow (Google) – Comprehensive framework with strong production support
- PyTorch (Meta) – Popular for research and rapid prototyping
- scikit-learn – Excellent for traditional machine learning
- XGBoost – Highly effective for structured data prediction tasks
Cloud AI Platforms
Most companies leverage cloud services rather than building everything from scratch:
- Google Cloud AI Platform – Full suite of managed services
- AWS SageMaker – Amazon’s end-to-end machine learning platform
- Azure Machine Learning – Microsoft’s offering with strong enterprise integration
- Hugging Face – Specialized for large language models and transformers
Data Infrastructure
Supporting thousands of AI models at scale requires robust data systems:
- Data warehouses (Snowflake, BigQuery, Redshift) – Centralized data storage
- Feature stores – Systems that manage preprocessed data features used across models
- ETL tools – Pipelines that extract, transform, and load data
- Data versioning tools – Track which data was used to train which models

How to Start AI Development: Practical Guidance
If your organization is considering AI initiatives, here’s practical guidance on getting started:
1. Start Small and Specific
Don’t attempt to transform your entire business with AI. Instead, identify one specific, measurable business problem where AI could add value. Examples:
- Predicting which support tickets will require escalation (saves support team time)
- Identifying high-value customers likely to churn (enables retention campaigns)
- Automating data entry from documents (reduces manual work)
- Recommending next products based on browsing (increases revenue)
A focused, successful project builds organizational capability and confidence for larger initiatives.
2. Audit Your Data
Before any AI project, assess your data situation:
- Do you have historical data for the problem you want to solve?
- Is data accessible from existing systems, or would extraction require significant engineering?
- What’s the data quality? Does it contain the information your model needs?
- Are there privacy/compliance considerations? (GDPR, HIPAA, etc.)
A project with mediocre algorithms and excellent data almost always outperforms one with excellent algorithms and mediocre data.
3. Build or Buy Decision
You don’t necessarily need to build models in-house:
- Buy pre-built solutions – Many vendors offer ready-made AI systems (recommendation engines, fraud detection, etc.)
- Use cloud AI services – Platforms like Google Cloud offer pre-trained models for common tasks
- Fine-tune existing models – Take a pre-trained large language model from OpenAI, Anthropic, or open-source projects and adapt it to your specific use case
- Build custom models – For truly unique competitive advantages or specialized problems
Most successful organizations use a hybrid approach: buying for commodity problems and building custom solutions for differentiated capabilities.
4. Assemble the Right Team
AI development requires diverse skills:
- Data engineers – Build data pipelines and infrastructure
- Machine learning engineers – Design and train models
- ML operations specialists – Deploy models and monitor production systems
- Domain experts – Understand the business problem deeply
- Product managers – Connect technical capabilities to business needs
You don’t need all these roles immediately, but you need clarity on who’s responsible for each function.
5. Plan for Iteration and Uncertainty
Traditional software has relatively predictable timelines. AI projects require more flexibility:
- Set realistic timelines – Account for data collection, cleaning, and multiple iteration cycles
- Build contingencies into budgets – Unexpected data quality issues or performance challenges are normal
- Plan for model evolution – Your first model will likely not be your final one
- Measure business impact early – Deploy a working model as soon as it’s better than the baseline, even if it’s not perfect
Key Benefits and Realistic Challenges
Benefits of AI Systems
When implemented thoughtfully, AI delivers substantial business value:
- Automation of repetitive work – Reduces manual tasks and human error
- Better decision-making – Provides data-driven insights for complex decisions
- Improved personalization – Delivers experiences tailored to individual customers
- Faster problem detection – Identifies issues before they impact customers
- Competitive advantage – Novel AI capabilities can differentiate your offering
- Scalability – Handle growing volume without proportional cost increases
Genuine Challenges
Honest assessment requires acknowledging significant challenges:
- Data quality and availability – Collecting sufficient, clean, representative data is harder than anticipated
- Model performance on edge cases – Systems that work well on average often fail on unusual situations
- Bias and fairness – AI systems inherit biases from training data and can perpetuate discrimination
- Interpretability – Some AI models are “black boxes”—it’s unclear why they made specific decisions
- Regulatory uncertainty – AI regulation is evolving, and compliance requirements are still being defined
- Organizational change management – Teams must adapt to AI capabilities and limitations
- Ongoing maintenance burden – Models require monitoring and retraining as conditions change
- High upfront investment – Building AI capability requires substantial investment before returns materialize
Successful organizations acknowledge these challenges rather than ignoring them. They invest in data quality, establish governance processes, and plan for long-term AI operations rather than treating it as a one-time project.
The Future of AI Development
The field is evolving rapidly. Several trends will shape how AI gets built:
Improved Pre-trained Models
Companies like OpenAI, Google, and Anthropic have demonstrated that large models trained on massive datasets can solve many problems with minimal task-specific training. This “foundation model” approach may reduce the need for custom model development for many use cases.
Reduced Technical Barriers
No-code and low-code platforms are making AI accessible to non-specialists. While custom AI will always require specialized expertise, routine AI applications are becoming more democratized.
Responsible AI and Governance
Organizations increasingly recognize that unconstrained AI optimization can cause harm. We’ll see more attention to fairness, transparency, and human oversight in AI systems.
Integration with Existing Workflows
Rather than standalone AI projects, we’ll see AI capabilities embedded into existing software tools and business processes.
Conclusion
Understanding how AI gets built and deployed is increasingly essential for business leaders, CTOs, product managers, and anyone involved in technology decisions.
The AI development meaning is simple: it’s the process of creating software systems that learn from data rather than following explicit instructions. But the practice is nuanced, requiring attention to data quality, realistic performance expectations, ongoing maintenance, and thoughtful integration into your business.
Your organization doesn’t need to become a machine learning research lab to benefit from AI. But you do need to understand the basics of how AI systems are built, the resources required, realistic timelines, and the genuine challenges involved.
Start with a focused, specific problem. Assess your data. Assemble or partner with the right expertise. Plan for iteration. Measure business impact, not just technical metrics. And build organizational capability for the long term.
AI is not a one-time project, it’s a new capability your organization needs to develop thoughtfully and sustain operationally. With that realistic foundation, your organization can successfully implement AI solutions that drive meaningful business value.